7 Essential Steps and Examples to Implement SCA Scanning
SCA scanning surfaces vulnerabilities in your third party libraries, but its impact will depend on how you implement it in your SDLC. Follow the steps below to learn how to get the most out of your SCA initiative.
Updated November 26, 2024

While development teams rely on open source components to build applications faster, many open source libraries contain vulnerabilities that can find their way to production. Between 2019 and 2022, the number of software packages affected by supply chain attacks worldwide jumped from 702 to a staggering 185,572.
Software Composition Analysis (SCA) technology can automatically identify third party libraries in your code base, while flagging lurking vulnerabilities that could have otherwise gone unnoticed.
This article will break down how SCA works, and the steps needed to implement open source security into your DevSecOps toolchain.
How Software Composition Analysis (SCA) works
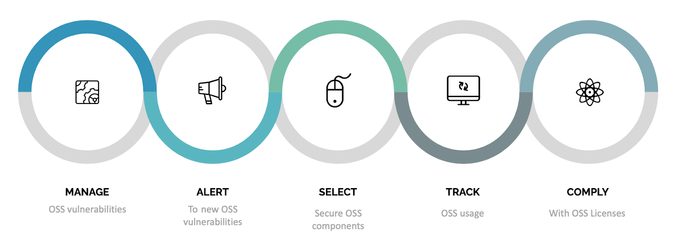
Software Composition Analysis (SCA) scans your open-source software (OSS) components and libraries to help ascertain whether an application, code base, container, or binary contains known security vulnerabilities.
It spots these vulnerabilities by analyzing the product’s dependencies (name and version used) and comparing them to known vulnerability databases.
To do it manually, engineers would need to examine a vulnerability database like NVD (National Vulnerability Database, managed by NIST) and compare it with their current dependencies.
NVD updates its “year” feeds once a day, while the “recent” and “modified” feeds are updated every two hours. This means your engineers would have to update their dependencies just as frequently.
Modern implementations of SCA integrates automated scanning into the SDLC. For example, rather than manually analyzing your code after every change, SDLC integrations will automatically scan your code in the IDE, during the build, or other insertion points.
In doing so, SCA helps you address vulnerabilities before they can be exploited through attacks such as SQL injection and Cross-Site Scripting (XSS).
For example, with XSS attacks, SCA can flag third-party code imported from libraries that doesn’t validate or sanitize user input, a common cause of XSS vulnerabilities.
7 Steps and Examples to Implement SCA Scanning
1. Evaluate SCA scanning tools for your environment
Each language and potentially even build system could handle component listing differently. Therefore, ensuring your chosen SCA solution supports your coding languages is crucial.
Most SCA tools rely on manifest and lock files such as Pipfile.lock, Package.json, or package-lock.json to find components and their respective versions. Remember that if you’re using a language not covered by your SCA tool, you’ll never find any vulnerabilities in it since your tool won’t be able to check it properly.
Here are some options to get started:
NPM Audit: Surface known vulnerabilities in open source components written in Javascript or Typescript. NPM-audit is powered by the GitHub Advisory Database.
OSV Scanner: Use OSV-Scanner (by Google) to find existing vulnerabilities affecting your project’s dependencies. The tool uses the data provided by https://osv.dev. Support Python and PHP.
Nancy: Nancy surfaces known vulnerabilities in open source components written in Go.
Jit automates the implementation for the tools above. Simply install Jit in the GitHub Marketplace, and activate SCA scanning to scan all of your repos, while also integrating continuous scanning into every PR created for your repos. >> Explore our complete list of SCA scanners
2. Integrate SCA scanning early in the SDLC
A core principle of the Secure Software Development Life Cycle is to surface security issues before production. Any security issue you find later in the SDLC stage usually requires getting the code back to development for correction, which can be burdensome and time-consuming.
Therefore, we want to get as clean a version of the application as possible into the CI/CD pipeline. That’s why your SCA tool should be easily integrated with your developer’s IDE, while creating PRs in the SCM, during the build, or using another SDLC insertion point.
In the example below, you can see what the user experience looks like for scanning open source libraries in the IDE using Jit.
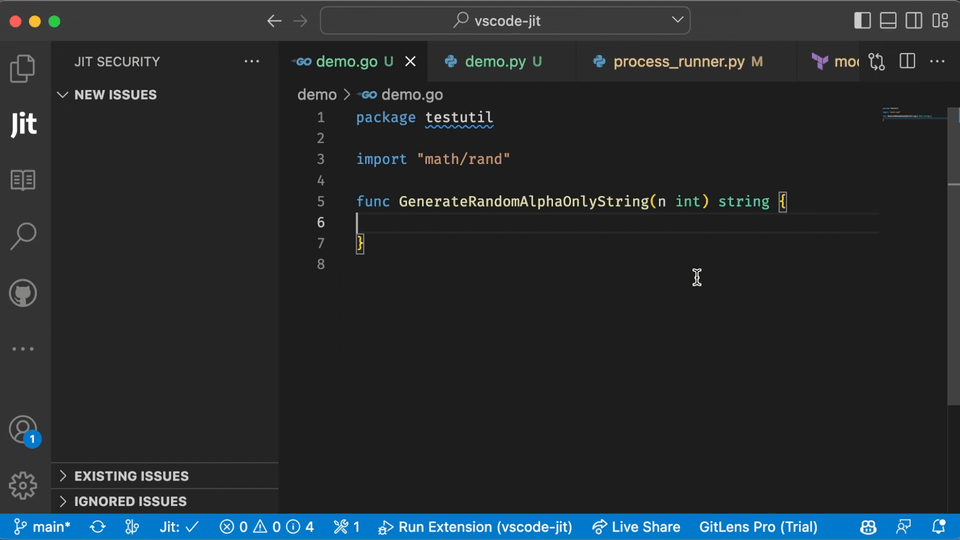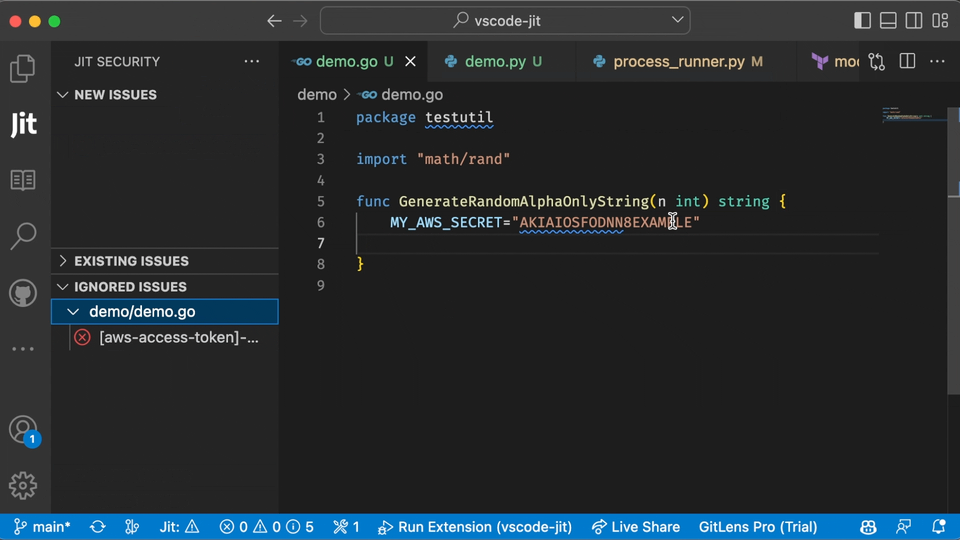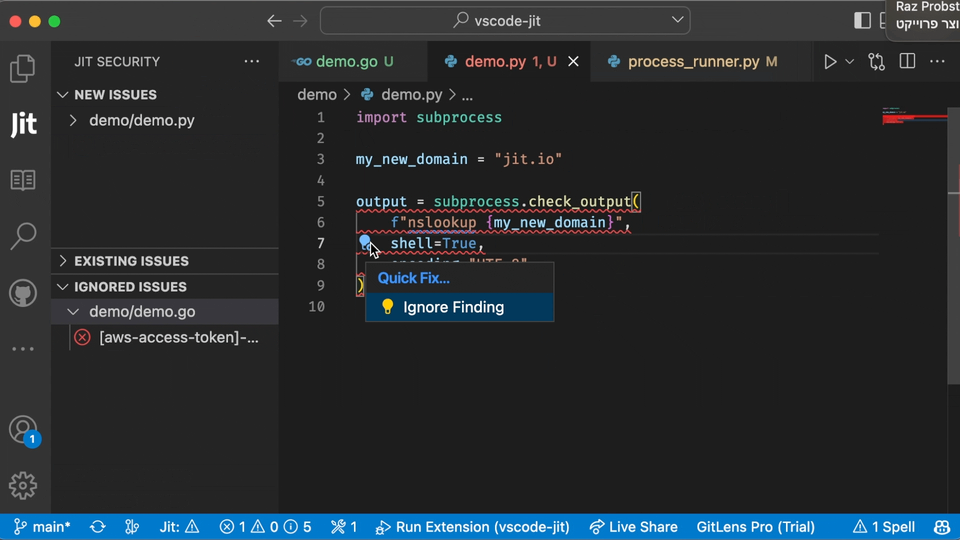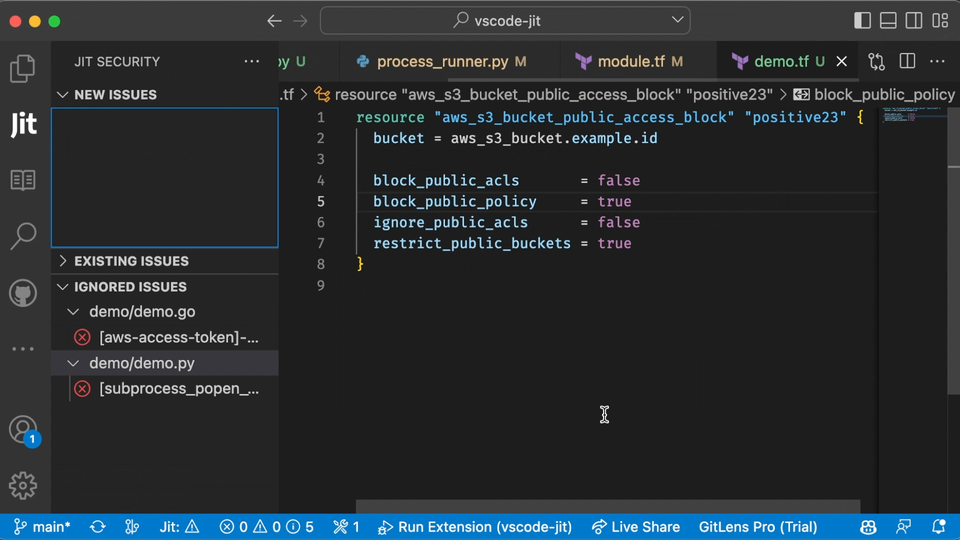
Finding vulnerabilities early is always better than finding them in production. However, many security teams will prefer to scan codebases in production to ensure nothing falls through the cracks.
Using multiple SDLC insertion points can contribute to a more holistic security strategy and give you more confidence in the safety of your software.
3. Provide security feedback for every pull request
Taking developers out of their flow state can distract them from the core task at hand: delivering new features quickly.
For this reason, it's best to provide immediate feedback on the security of their code change, rather than providing a long list of vulnerabilities that aren’t relevant to their current pull request. This reduces security issues to the most important in that moment: the issues that are about to be pushed to production. In the example below, you can see how SCA scanning can be executed within the pull request, so developers can quickly address the problem before pushing it to production.
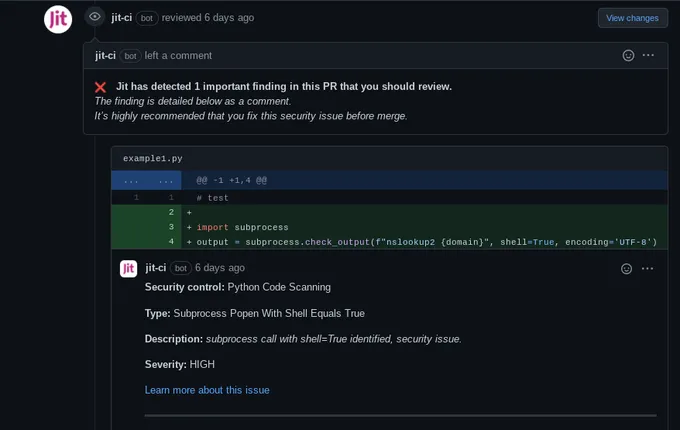
4. Use integrations that enhance your Source Code Manager (SCM)
In order to fulfill the previous step, you’ll need tooling that integrates natively with your SCM to scan and monitor every change. While most tools will have an “integration” with GitHub, for example, they won’t be able to provide immediate security feedback within every PR.
When SCA scanning is embedded into the SCM, it feels like an extension of your SCM rather than an entirely separate security tool, which makes it easier for developers to adopt into their day-to-day routines.
Security orchestration for GitHub is an effective way to ensure full coverage across all of your repos, without ever requiring the developer to leave their environment or flow state.
5. Integrate with Issue Tracking
Getting a JSON file at the end of your scan with a list of potential vulnerabilities isn’t usually very actionable. Developers may ask themselves, what do I do from here? What should I prioritize? Who should I assign this to?
SCA scanning may become shelfware unless easily integrated into the company’s task management system to provide actionable next steps for remediation. Whatever tool you use to track issues and tasks for your security and R&D team, be it Monday, Jira, or Confluence, arrange for your SCA results to be automatically sent to the proper team or person.
It helps if your tool also offers remediation suggestions for each vulnerability.
Jit enables you to send your test results directly to Jira. By modifying your jit-integration.yml file (adding your API token and relevant JIRA data to this file), you can integrate your Jit scanning results seamlessly with Jira. Here’s what the yml file template looks like:
jira:
jira-engineering:
auth:
api_token: ${{ jit_secrets.jira-token }}
email: requester@company.io
domain: extract_from_jira
preferences:
project_id: 10001
issue_type_id: 10002
fields:
customfield_10034:
- value: "1"
6. Create security policies for your SCA scanning
Whether or not the SCA tool you integrate knows how to handle security policies, you should create those yourself and apply them to the scan results.
The more granular you can get in using the SCA information, the better for your users. As an example, Jit provides enriched findings combining the results from several tools, so you’re more likely to find valuable insights you could use for such policies.
Some examples of policies might include:
Do not allow any open-source license that is not permissive.
Do not allow a build to be distributed with high or critical vulnerabilities.
Do not allow a component with a known vulnerability and a known patch that you can fix (why fix it later when you can fix it now?).
Such policies make it easy to avoid manual reviews of vulnerabilities to determine what needs to be fixed.
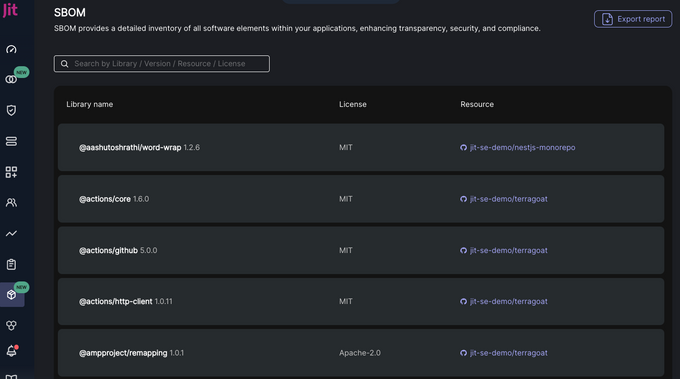
7. Consider SBOM to document third party dependencies
Many customers are requiring vendors to provide a Software Bill of Materials (SBOM), which catalogs every open source library within your code base. Customers can use this information whenever new security vulnerabilities are disclosed, so they can verify their third-party risk. SBOM is a byproduct of many SCA tools, but even if your tool doesn't create one, there are free, open-source tools (like Syft) you can use to make one for your product and keep it updated.
Once you have a solid SBOM, use that list of components to track new vulnerabilities, newer versions of packages, and packages that have reached end-of-life or are no longer maintained.
Even if your next product version is not yet ready, you might already be able to provide developers with security updates on components they have previously included. Below is an example of the software component inventory SBOM tools can produce:
Post-SCA: Optimizing application security at all stages
While SCA scanning covers security for your third party dependencies, there can be many other vulnerabilities lurking in your source code, IaC files, container images, and other parts of your system.
You may need additional security technologies like SAST, secrets detection, IaC scanning, Cloud Posture Security Management (CSPM), and other tools to surface vulnerabilities undetectable by SCA.
At Jit, we unify the entire code-to-cloud security tool set in one place, so you can get full coverage in a matter of minutes. All security scanning is delivered entirely within the PR or IDE with exceptionally fast scan times, so it's easy for developers to get started. Explore more here.